

はじめに:なぜSUUMOの物件データを収集するのか?
賃貸住宅を探している方も、賃貸経営を検討している方も、共通して重要となるのが「情報収集」です。SUUMOのような大手不動産情報サイトは膨大な物件情報を提供してくれますが、一つ一つ手作業で情報を集め、比較検討するのは非常に手間がかかります。
特に、以下のような課題を感じている方も多いのではないでしょうか?
- (賃貸を探す方)膨大な物件の中から、自分の条件に合う最適な部屋を見つけたいが、比較が大変。
- (賃貸経営を検討する方)特定のエリアや条件での正確な家賃相場や競合物件情報を効率的に知りたい。
- データを加工して独自の分析をしたいが、手入力では限界がある。
- 市場全体の傾向をデータで把握し、より戦略的な意思決定を行いたい。
そんな課題を解決するのが、今回ご紹介する「SUUMO物件データ収集ツール」です。このツールを使えば、あなたがSUUMOで設定した検索条件に合致するすべての賃貸物件情報を自動で収集し、Excelなどで加工しやすいCSV形式で出力できます。
このツールは、Pythonの知識が全くなくても、Googleアカウントさえあれば誰でも簡単に利用できます。
このツールでできること
「SUUMO物件データ収集ツール」は、以下のような点であなたの情報収集と分析を強力にサポートします。
- 検索結果全ページの賃貸物件情報を一括取得:
- SUUMOで設定した検索条件(地域、家賃、間取り、築年数など)に合致する物件の、最大数百ページにも及ぶ情報を自動で巡回し、漏れなく取得します。
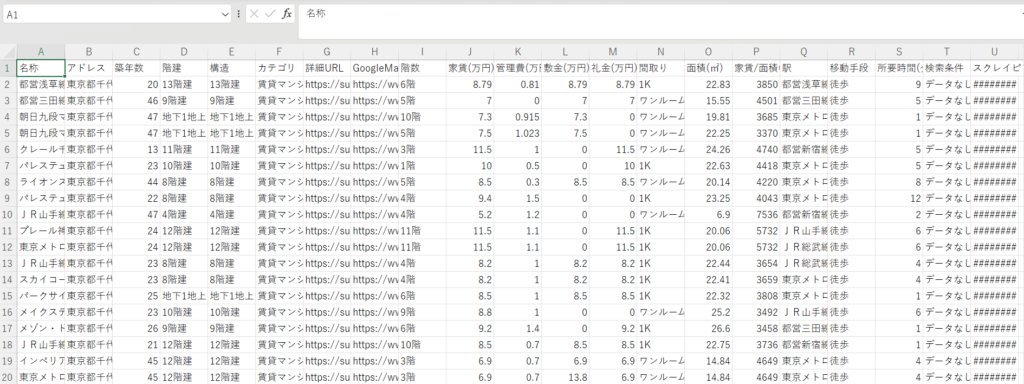
- 賃貸探し・経営判断に必須の情報を厳選して抽出:
- 物件名、住所、築年数、階数、構造、家賃、管理費、敷金、礼金、間取り、専有面積、最寄り駅、駅からの所要時間、Googleマップへのリンクなど、賃貸住宅選びや賃貸経営判断に必須の情報を自動で抽出します。
- 「家賃/面積(円/㎡)」を自動算出:
- 坪単価ならぬ「㎡単価」を自動で算出し、物件の家賃効率を比較しやすくします。これにより、同じ面積あたりの家賃を簡単に比較検討でき、賃貸物件の掘り出し物を見つけたり、適正な賃料設定の参考にしたりできます。
- 加工しやすいCSV形式で出力:
- 抽出されたデータはExcelやGoogleスプレッドシートで開けるCSVファイルとして出力されます。これにより、独自の条件で並び替えたり、グラフを作成したり、特定のエリアや条件における家賃相場、築年数と家賃の関係、広さと家賃の関係などを多角的に分析することが可能になります。
- Googleマップリンクの自動生成:
- 各物件の住所からGoogleマップへのダイレクトリンクを自動生成するため、物件の所在地や周辺環境確認がスムーズに行えます。
<こんな方におすすめ>
- 効率的に理想の賃貸住宅を見つけたい方
- 引越し先の家賃相場やエリアの情報を深く知りたい方
- 不動産投資を検討しており、物件の市場調査を効率化したい方
- 現在保有している賃貸物件の適正家賃を検討したい方
- データ分析に興味があるが、プログラミングは苦手な方
- 賃貸物件情報のデータベースを自分で作りたい方
ツール利用方法(Google Colaboratoryを利用)
このツールは、Googleが無料で提供している「Google Colaboratory(通称:Colab)」というサービスを使って実行します。Colabは、ウェブブラウザ上でPythonのプログラムを実行できる環境なので、あなたのパソコンにPythonをインストールする必要は一切ありません。Googleアカウントさえあれば、誰でもすぐに利用できます。
【重要】
- スクレイピングは、対象ウェブサイトのサーバーに負荷をかける行為であり、サイトの利用規約で禁止されている場合があります。本ツールのご利用はSUUMOの利用規約に反しない範囲での個人利用に留めていただき、自己責任でお願いいたします。 大量かつ頻繁なアクセスは控えてください。
- SUUMOのウェブサイトの構造が変更された場合、本ツールが正常に動作しなくなる可能性があります。
- https://suumo.jp/jj/chintai/ichiran/ ●●● のような形のURLを本ツールに入力してください(駅や区市などで検索した後のURL)。これ以外のURLでは動作はできません。
具体的な実行手順は、以下のnote記事で詳細に解説しています。
まとめと次のステップ
SUUMO物件データ収集ツールを活用することで、あなたの賃貸探しや賃貸経営における情報収集プロセスが劇的に効率化されます。データに基づいた賢い意思決定のために、ぜひこのツールを活用してみてください。
このツールの具体的な使い方と、実際にあなたが実行できるGoogle Colabノートブックへのアクセス方法は、**以下のnote記事(一部有料)**で詳しく解説しています。
有料部分では、実際にコードが埋め込まれたGoogle Colabノートブックへのリンクを提供しています。コピーするだけで、すぐに実行できる状態になっていますので、ぜひご活用ください。


コメント